面向目标的导航调研
根据导航目标分类可以分为
- Object-goal Navigation (对象目标导航)
- Instance-image-goal Navigation (实例图像目标导航)
- Text-goal Navigation (文本目标导航)
需要实现如下的能力:
- 语义/图片级别的目标理解(到厨房找黑色垃圾桶,到卧室找一个蓝色的灯,找到这个图片的位置)
- 空间推理,能够理解场景的之间的关联,例如找冰箱先去厨房,找床就要去卧室,找马桶要去洗手间
根据方法可以分为端到端的导航和模块化导航,其中区别如下图所示

-
端到端的导航通过视觉编码器和语言描述编码器得到当前图像和目标位置的特征,然后训练一个策略网络,根据这两个特征进行判断到底往哪个方向走,没有一个显式构建地图的过程,也没有显式的逻辑推理过程,一切都是端到端训练出来的。
-
模块化的导航利用了现有的定位建图方法,然后用显式的方式调用大模型的理解和推理能力
- 构建几何地图,用传统方法找到哪些方向可能有没有被探索的区域
- 构建语义地图,调用图像大模型进行目标识别/语义分割,建立语义地图(各种语义地图表达方法不同)
- 将语义地图转换为文本,调用大模型推理判断哪些地方可能出现目标
- 寻找最有可能出现目标的位置,设置目标点为该位置,然后走过去
端到端导航(强化/模仿学习)
Auxiliary tasks and exploration enable object goal navigation

输入:
- 图像
- 语义分割结果
- GPS+磁力计
输出: - 机器人动作
Thda: Treasure hunt data augmentation for semantic navigation
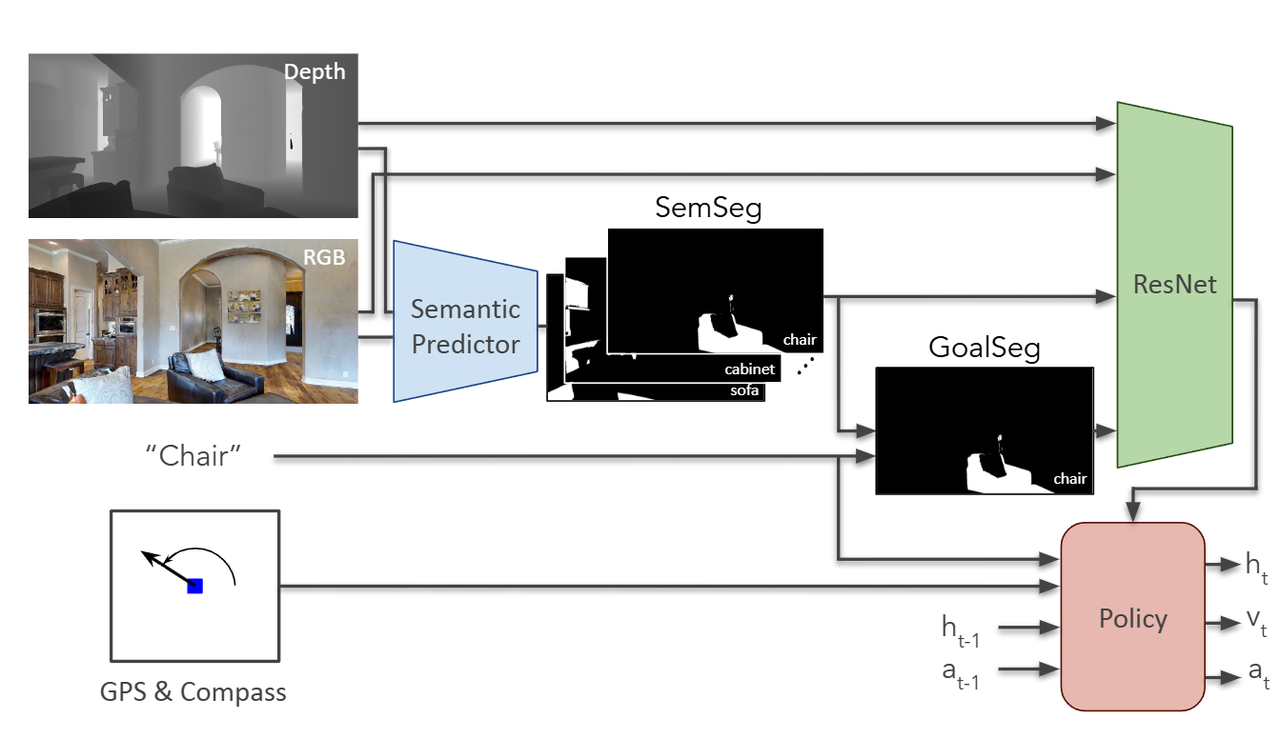
输入:
- 图像
- 深度
- 语义分割结果
- GPS+磁力计
输出: - 机器人动作
Zson: Zero-shot object-goal navigation using multimodal goal embeddings, 2022, ICCV
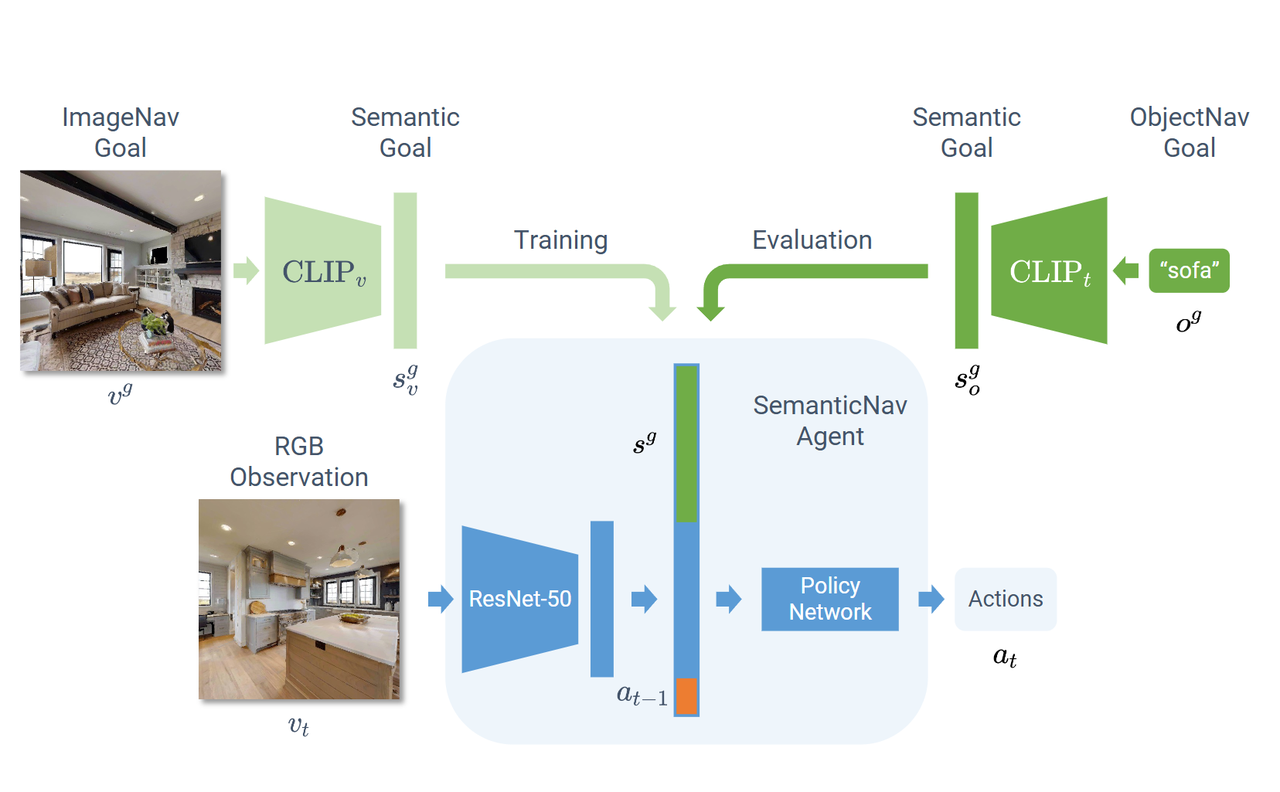
Visual semantic navigation using scene priors,2018
DD-PPO: Learning Near-Perfect PointGoal Navigators from 2.5 Billion Frames, 2019, ICRA
Visual representations for semantic target driven navigation, 2019
Auxiliary tasks and exploration enable object goal navigation, 2021, ICCV
Thda: Treasure hunt data augmentation for semantic navigation, 2021, ICCV
Hierarchical object-to-zone graph for object navigation, 2021, ICCV
Zson: Zero-shot object-goal navigation using multimodal goal embeddings, 2022, ICCV
模块化导航方法(大语言/视觉模型)
零样本导航(无需训练)
Esc: Exploration with soft commonsense constraints for zero-shot object navigation, 2023, ICML
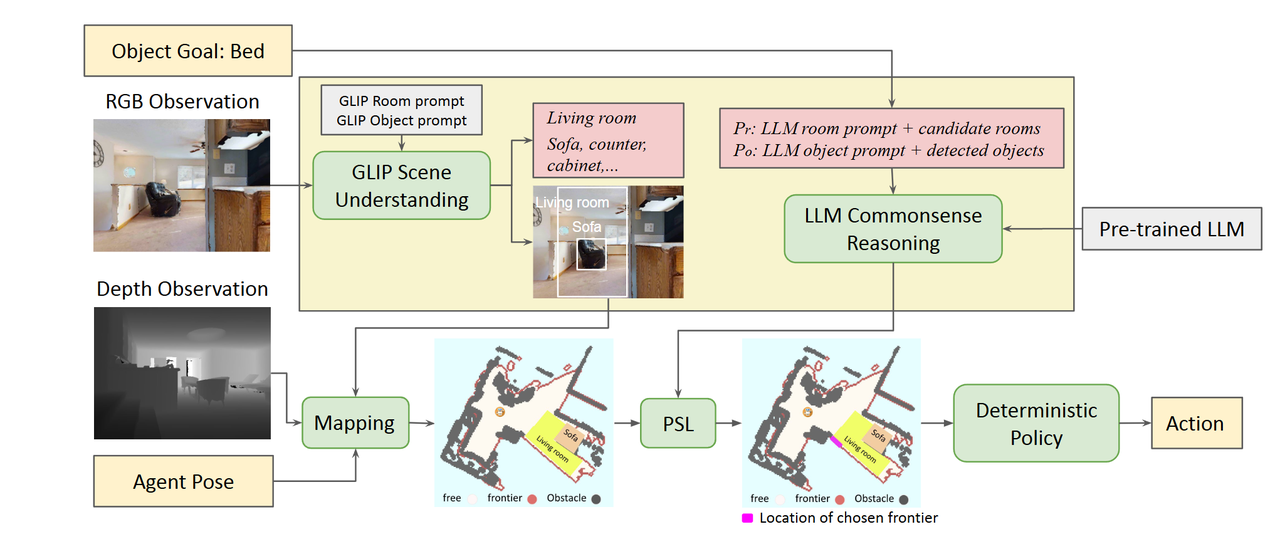
传统方法
输入:
- 深度图
- 位置
输出:
- 2d栅格地图
- 地图前沿(没有被探索过的部分,可能存在目标的区域)
学习方法
-
场景理解
- 识别当前环境是厨房、客厅还是卧室,还是在什么环境内
- 识别环境中的物体,有凳子,桌子,有沙发,等等
-
场景推理
- 当前场景中有的物体,推理目标物体最有可能出现的区域。
最后,结合未探索的区域和大模型的推理结果,设置目标点让机器人走过去
Goat: Go to anything
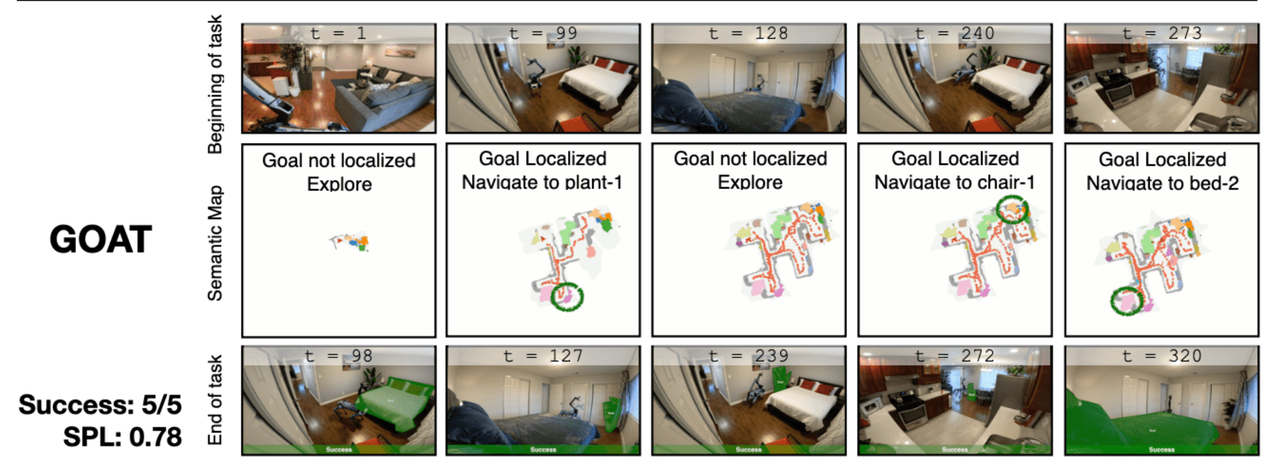
额外添加了一个功能:
传统方法构建语义地图 --> 语义地图转换为文本给大模型 --> 推理最有可能出现目标位置的地方
区别在于,不止采用当前看到的图像推理,还用之前看到过的图像构建的语义地图辅助推理,这样搜索能力更强。
SG-Nav: Online 3D Scene Graph Prompting for LLM-based Zero-shot Object Navigation, 2024, NeurIPS
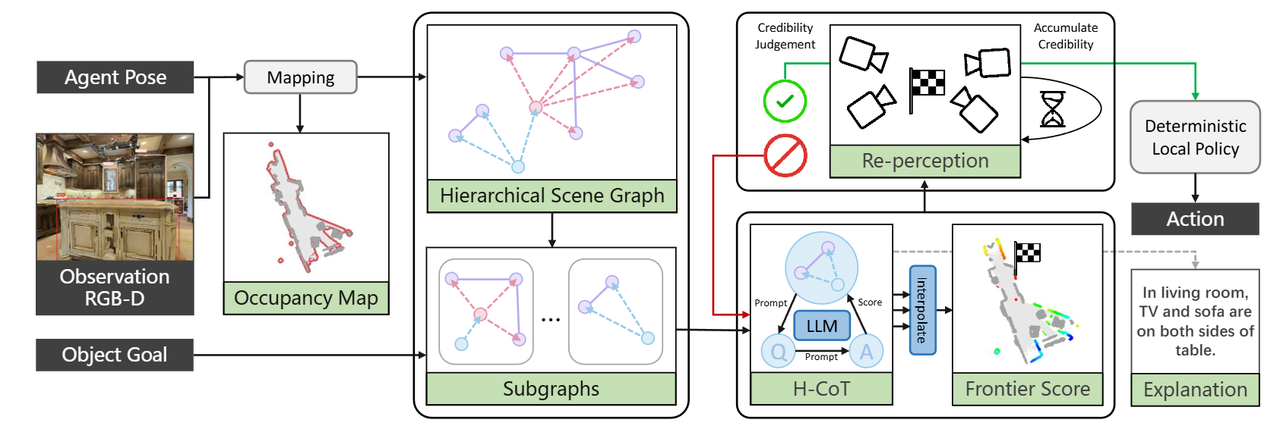
不使用传统的语义地图,而是更容易被大语言模型的分层拓扑语义地图表达,推理能力更强。
例如,一个文本描述的语义地图:
卧室里面有床、有柜子、有窗户、有衣服。柜子在床左边,窗户在床的右边,衣服在床上
VL-Nav: Real-time Vision-Language Navigation with Spatial Reasoning, 2025, RAL

这个方法类似第一种方法
识别当前场景中的所有物体,然后用大模型推理哪个方向上最有可能出现目标,然后就朝着哪个方向走,优势就是快。
Object Goal Navigation using Goal-Oriented Semantic Exploration, 2020
Open-vocabulary queryable scene representations for real world planning, 2023, ICRA
Esc: Exploration with soft commonsense constraints for zero-shot object navigation, 2023, ICML
Navigating to objects specified by images, 2023, ICCV
Goat: Go to anything, 2023
InstructNav: Zero-shot System for Generic Instruction Navigation in Unexplored Environment, 2024
Vlfm: Vision-language frontier maps for zero-shot semantic navigation, 2024, ICRA
Prioritized semantic learning for zero-shot instance navigation, 2024
SG-Nav: Online 3D Scene Graph Prompting for LLM-based Zero-shot Object Navigation, 2024, NeurIPS
VL-Nav: Real-time Vision-Language Navigation with Spatial Reasoning, 2025, RAL
UniGoal: Towards Universal Zero-shot Goal-oriented Navigation, 2025, CVPR


