从传统光流到端到端的光流
一、从直觉出发——光流该如何估计
什么是光流?
- 光流(optical flow)是「像素运动」的场。
- 直观来说,就是相邻两帧之间「每个像素往哪里跑了」。
想象:
你看一段视频,盯住一块特征花纹,它从第1帧的 (x, y) 移动到第2帧的 (x+u, y+v)。那么光流就是 (u, v)。
🌟 观点1:从像素层面估计光流
1️⃣ 假设亮度和纹理在运动中保持大致不变
想象你看到视频里的一个小花纹块,它虽然动了,但形状和亮度大体没变。
也就是说,它只是位置发生了变化。
2️⃣ 在两张相邻帧之间寻找最相似的位置
直觉上,我们可以在第二张图片上「到处找」,看如果把这个块「平移」过去,哪里和原来最像。
✅ 我们试着往一个方向挪一点,看相似度好不好;
✅ 如果不够像,就换个方向继续试;
✅ 最后找到一个相似性最高的位置,就说它运动了这么远。
3️⃣ 多次迭代、精细调整位置
由于一次挪动可能找不准,常常需要多次「微调」。
就好像你在人群里找朋友,你先大概看一圈,然后慢慢走近对上细节。
4️⃣ 全局约束:让运动场平滑
但只靠局部相似会出错,比如纯色区域、模糊区域信息不足。
所以我们还会「假设」周围像素的运动不会差太多。
直观来说:“如果这一小块整体都在动,那么里面的点也会差不多一起动。”
✅ 这就避免了噪声、空洞、歧义。
5️⃣ 最终输出每个像素的位移向量
当我们对整张图片都做完这个「寻找最相似位置 + 平滑约束」的过程后,
我们就得到一个「运动场」——告诉我们每个像素往哪个方向、移动了多少。
🌟 极简的直觉总结
✅ 先看这个像素块在第一帧长什么样;
✅ 在第二帧里找哪里最像;
✅ 允许微调对齐;
✅ 假设附近像素运动差不多;
✅ 最后得到全图每个像素的位移向量。
🌟 观点2:对世界的理解才能真正解决光流估计
① 特征追踪(理解图像中哪些点是好跟踪)
- 不再盯着亮度像素,而是找「好认的点」。
- 比如角点、特征点、花纹独特的块。
- 在下一帧找「那个点最像出现在哪」。
✅ 直觉类比:
你在人群里找朋友,不会盯着路面纹理,而是记住他衣服、头发特征。
✅ 特点:
- 先找到可跟踪的点(比如Harris角点)
- 只在这些点上找运动
- 适合稀疏光流,但直观且鲁棒。
② 物体刚体/非刚体运动模型 (理解刚体运动)
- 先假设某些区域是刚体,整体平移或旋转。
- 估计运动是「参数化」的,比如仿射或透视变换。
✅ 直觉类比:
看一张硬纸片在画面里转动,不是每个像素随意跑,而是整体转动。
✅ 特点:
- 用少量参数就能解释区域运动
- 更适合大物体的全局运动估计。
③ 语义一致性 (理解语义信息)
- 不只看亮度,还看「语义分割」:物体类别要一致。
- 例如同一个车的所有像素要一起动。
✅ 直觉类比:
「那是同一辆车,整体要一起运动。」
✅ 特点:
- 融合了高层信息
- 现代深度学习光流模型里会用。
总结流程图
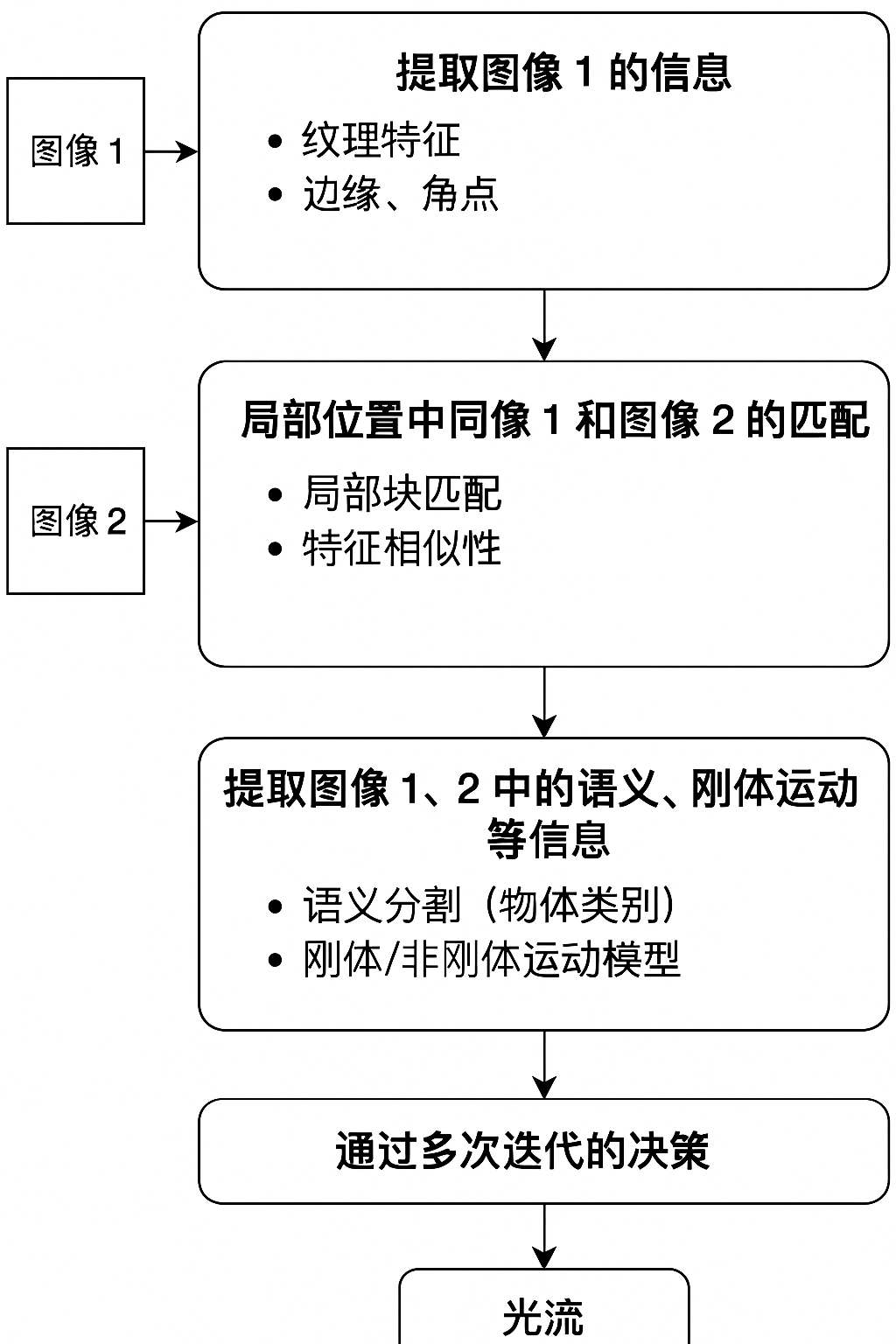
二、传统LK光流的解读
Lucas-Kanade 光流(LK光流)是最经典的局部光流估计算法之一,最早是1981年提出的。它的核心思想非常简单直观:
🌟 「在一小块区域里,假设所有像素运动一样,然后在第二帧里找到那个平移量,让这个区域的亮度变化最小。」
1️⃣ 背后的假设
LK光流建立在两个主要假设上:
✅ 亮度一致性假设
物体运动前后,局部亮度不变。
✅ 局部平移假设
在一个小窗口里,所有像素的运动是相同的(同一个(u,v))。
2️⃣ 公式直观推导
把亮度一致性做泰勒展开(小运动线性近似):
- 这是光流约束方程,但只有一个方程,两个未知数(u, v)。
- 单个像素解不了,需要多个像素一起用。
LK光流的关键是:
在一个窗口内收集多个像素的约束,共同解一个(u,v)。
在窗口里的所有像素满足:
用最小二乘解这个方程组,得到局部运动向量 (u, v)。
3️⃣ 直觉解释
✅ 先在第一帧里找一个小窗口
✅ 记录这个窗口里的亮度结构(梯度信息)
✅ 假设这个窗口整体平移
✅ 在第二帧里找那个平移量,让亮度变化最小
✅ 得到运动向量 (u, v)
很好,接下来我们继续第二步:把刚才那张流程图的步骤对照起来,分析 LK 光流用了哪些信息、没用哪些信息,因此有什么优势和劣势。
对照直觉的逻辑,LK光流做对了什么
① 提取图像1的信息
✅ LK光流确实做了
- 提取 局部亮度梯度(Ix, Iy)
- 选择「纹理丰富的点」作为跟踪点(角点、特征点)
直觉:
先找到「好认的地方」,并在这些位置记录纹理信息。
② 建立局部匹配关系
✅ LK光流的核心就是这一步
- 在第二帧里找小块的最优平移
- 通过亮度一致性,解局部平移 (u,v)
直觉:
假设这个块整体平移,找到最相似的位置。
③ 提取语义、刚体运动等信息 ✘
❌ LK光流完全没有用到:
- 语义信息(不知道物体类别)
- 刚体/非刚体运动模型(不建模旋转、缩放、变形)
直觉缺陷:
它只在「非常小的窗口」里做平移匹配,忽略大物体的整体结构或运动规律。
④ 通过多次迭代的优化 ⚠️ 部分用到
-
基础 LK:不迭代,一次解。
-
金字塔 LK(常用版):做了多尺度迭代
- 先在低分辨率粗略对齐
- 再在高分辨率细调
✅ 所以这步 LK 是「可选地部分用到了」。
✅ 总结表
| 流程步骤 | LK光流用了吗? | 说明 |
|---|---|---|
| 1️⃣ 提取图像1的局部信息 | ✔️ 用了 | 计算梯度、选择角点 |
| 2️⃣ 局部匹配 | ✔️ 用了 | 小块平移、亮度一致性 |
| 3️⃣ 语义、刚体运动先验信息 | ✘ 没有用 | 没有物体分割或刚体模型 |
| 4️⃣ 多次迭代优化 | ⚠️ 部分用(在金字塔版里) | 粗到细多尺度匹配,但没有全局能量优化 |
| 5️⃣ 输出像素级光流 | ⚠️ 稀疏版本 | 只在角点/网格上输出,非全局稠密流场 |
✅ 🌟 因此带来的优势
✔️ 简单易实现
线性方程组,计算快
✔️ 在纹理丰富区域很准
梯度信息好,解稳定
✔️ 可用多尺度迭代扩展到中等大运动
金字塔版很实用
✔️ 高效适用于实时跟踪
用在特征点追踪、小运动场景
✅ 🌟 因此带来的劣势
❌ 只能局部平移模型
不能处理旋转、仿射、透视、关节变形
❌ 没有全局平滑/一致性
稀疏光流,无法补全无纹理区域
❌ 无法利用语义信息
不知道物体是什么,不会分割前景背景
❌ 亮度一致性限制
对光照变化很敏感
三、RAFT光流流程
RAFT(Recurrent All-Pairs Field Transforms) 是2020年推出的深度学习光流方法,它非常有代表性,因为它把光流估计变成了一个全局、迭代优化的匹配问题。
⭐ ① 提取图像1的信息 ✅
✅ RAFT用到了
- 不只是亮度,还用CNN提取深度特征
- 学到的特征可以编码纹理、结构、甚至一些高层信息
优势:
对光照变化、噪声、复杂纹理都更鲁棒。
⭐ ② 建立局部位置的匹配关系 ✅✅
✅ 这是RAFT的核心
- 所有像素对 → 相关性体积
- 不是只在局部搜索,而是全局搜索
优势:
能对付大位移、复杂变形。
⭐ ③ 提取语义、刚体运动等信息 ⚠️ 部分用到
✅ RAFT没有显式语义分割或刚体建模
❌ 没有单独预测「这是一辆车」或「这是刚体旋转」
✅ 但它隐式学会了这些模式
- 在大数据上训练
- 网络特征可编码出物体级运动规律
总结:
没有显式先验,但学到隐式先验。
⭐ ④ 通过多次迭代的决策优化 ✅✅
✅ RAFT非常依赖这一步
- 用一个RNN迭代更新流场
- 每一步都在细化、优化结果
优势:
不是一拍脑门的单步解,而是多次细想。
✅ 总结表
| 流程步骤 | RAFT用了吗? | 说明 |
|---|---|---|
| 1️⃣ 提取图像1的局部信息 | ✔️ 用了深度CNN特征 | 鲁棒对光照变化 |
| 2️⃣ 建立匹配关系 | ✔️ 全局相关性体积 | 所有像素对都比较 |
| 3️⃣ 语义、刚体先验信息 | ⚠️ 隐式学到,不显式输入 | 通过训练数据学会物体运动模式 |
| 4️⃣ 多次迭代优化 | ✔️ 关键部分 | RNN反复更新光流 |
| 5️⃣ 输出像素级光流 | ✔️ 稠密预测 | 全分辨率输出 |
✅ 🌟 RAFT的劣势
❌ 没有显式语义分割或物体分层
不知道前景/背景、刚体/非刚体分开处理
❌ 高内存、高计算量
需要GPU,慢于传统LK
❌ 依赖大规模标注数据
要在很多视频/流场上训练才能表现好
LK 光流与RAFT光流的统一特性
- 提取Contex特征
- LK 光流提取当前帧的x, y 两个方向的梯度信息
- RAFT 只对当前帧提取 Context 特征
- 计算相关性
- LK光流计算平移之后的像素差
- RAFT计算平移之后提取的特征差异
- 迭代更新
- LK光流利用提取信息 以及相关性信息 ,求解方程得到更新量
- RAFT 利用GRU网络估计更新量


